最近最火的莫过于deepseek,听说deepseek的老板仅用了300万美元就干了openai几亿美元干成的事,国内外一片哗然。然而好景不长,人怕出名猪怕壮,deepseek的大火惹来了大量的攻击,当然也有可能是人数骤然增多,服务器带不动。现在问deepseek容易出现大量服务器繁忙的提示。
那么我们是不是可以自己搭一个??
Ollama
ollama是一款大模型工具,它让你更好,更迅速的使用大模型。

目前支持windows平台,支持linux平台以及macOS。传送门
linux服务器可以直接运行命令:
curl -fsSL https://ollama.com/install.sh | sh
如果是windows我们可以下载到本地。

下载后安装,并执行。然后打开
deepseek
关于DeepSeek
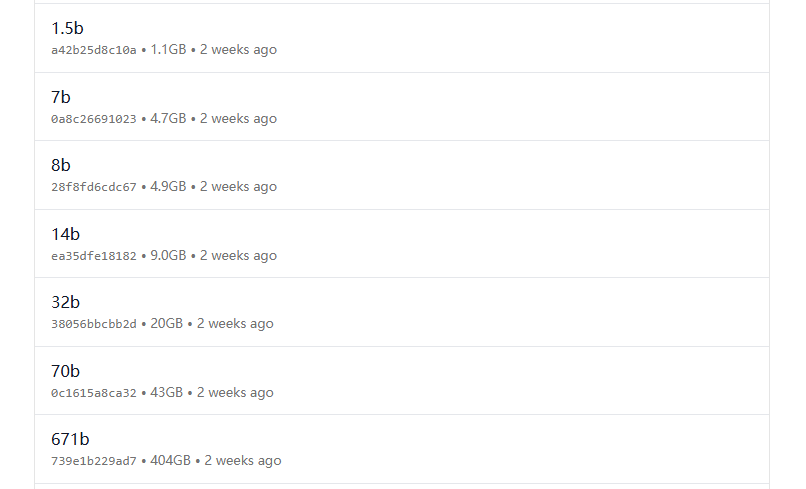
deepseek有四个模型:
11、R1模型,R1分为1.5b、7b、8b、14b、32b、70b和671b。1.5B、7B、8B、14B、32B、70B是蒸馏后的小模型,671B是基础大模型,它们的区别主要体现在参数规模、模型容量、性能表现、准确性、训练成本、推理成本上。

2、V1
3、V2
4、V3
全量模型671b需要两张24G的N卡。
有关配置需求如下
1. DeepSeek-R1-1.5B
CPU: 最低 4 核(推荐 Intel/AMD 多核处理器)
内存: 8GB+
硬盘: 3GB+ 存储空间(模型文件约 1.5-2GB)
显卡: 非必需(纯 CPU 推理),若 GPU 加速可选 4GB+ 显存(如 GTX 1650)
场景:低资源设备部署(如树莓派、旧款笔记本)
实时文本生成(聊天机器人、简单问答)
嵌入式系统或物联网设备
2. DeepSeek-R1-7B
CPU: 8 核以上(推荐现代多核 CPU)
内存: 16GB+
硬盘: 8GB+(模型文件约 4-5GB)
显卡: 推荐 8GB+ 显存(如 RTX 3070/4060)
场景:本地开发测试(中小型企业)
中等复杂度 NLP 任务(文本摘要、翻译)
轻量级多轮对话系统
3. DeepSeek-R1-8B
硬件需求: 与 7B 相近,略高 10-20%
场景:需更高精度的轻量级任务(如代码生成、逻辑推理)
4. DeepSeek-R1-14B
CPU: 12 核以上
内存: 32GB+
硬盘: 15GB+
显卡: 16GB+ 显存(如 RTX 4090 或 A5000)
场景:企业级复杂任务(合同分析、报告生成)
长文本理解与生成(书籍/论文辅助写作)
5. DeepSeek-R1-32B
CPU: 16 核以上(如 AMD Ryzen 9 或 Intel i9)
内存: 64GB+
硬盘: 30GB+
显卡: 24GB+ 显存(如 A100 40GB 或双卡 RTX 3090)
场景:高精度专业领域任务(医疗/法律咨询)
多模态任务预处理(需结合其他框架)
6. DeepSeek-R1-70B
CPU: 32 核以上(服务器级 CPU)
内存: 128GB+
硬盘: 70GB+
显卡: 多卡并行(如 2x A100 80GB 或 4x RTX 4090)
场景:科研机构/大型企业(金融预测、大规模数据分析)
高复杂度生成任务(创意写作、算法设计)
7. DeepSeek-R1-671B
CPU: 64 核以上(服务器集群)
内存: 512GB+
硬盘: 300GB+
显卡: 多节点分布式训练(如 8x A100/H100)
场景:国家级/超大规模 AI 研究(如气候建模、基因组分析)
通用人工智能(AGI)探索
安装步骤
如果我们已经安装好ollama以后,只需要运行下面的命令就可以静待好戏开场。
// deepseek-r1:8b 是需要根据自己的机器来调整的,最高的是671b,全量的deepseek,我这边机器是rtx2060,因此选择的是8b。
# ollama run deepseek-r1:8b